Копирование объектов в джаваскрипте
В джаваскрипте можно взять любой объект и поменять в нем какое-нибудь значение.
const obj = { a: 1, b: 2, c: 3 }
obj.b = 100
console.log(obj)
> { a: 1, b: 100, c: 3 };
Такой тип данных, когда значение можно менять, называют «мутабельным». В дословном переводе — «способный мутировать».
Работать с такими данными бывает неудобно. Можно случайно поменять значение переменной в одном месте, и не заметить, как во всей программе будет использоваться новое значение.
Предположим, нужно создать новый объект с такими же данными, как в исходном, но заменить в нем значение одного свойства. Вот что получится, если попробовать сделать это прямолинейным способом.
const obj = { a: 1, b: 2, c: 3 }
const objCopy = obj
objCopy.c = 100
console.log(objCopy)
> { a: 1, b: 2, c: 100 } // то, что и хотели
console.log(obj)
> { a: 1, b: 2, c: 100 } // свойство "c" в исходном объекте тоже изменилось
Исходный объект тоже почему-то поменялся, хотя его никто, казалось бы, не трогал. Дело в том, что objCopy тут на самом деле никакая не копия. В первой строчке, при объявлении obj где-то в недрах памяти создается объект, на который идентификатор obj будет ссылаться каждый раз, когда потребуется узнать его значение. Строчка objCopy = obj не создает новый объект, как можно было бы предположить, а создает новый идентификатор, который ссылается на тот же, уже существующий объект. В результате, при изменении любого из этих значений, будут меняться оба.
Как тогда сделать настоящую копию вместо ссылки на объект? Можно попробовать спред:
const obj = { a: 1, b: 2, c: 3 }
const objCopy = { ...obj }
objCopy.c = 100
console.log(objCopy)
> { a: 1, b: 2, c: 100 }
console.log(obj)
> { a: 1, b: 2, c: 3 } // сработало!
На самом деле нет. Спред копирует значение только на первом уровне, а дальше опять будут ссылки. Это называется shallow copy. Со вложенными объектами такой способ не работает:
const obj = { a: 1, b: { c: 3 } }
const objCopy = { ...obj }
objCopy.b.c = 100
console.log(objCopy)
> { a: 1, b: { c: 100 } }
console.log(obj)
> { a: 1, b: { c: 100 } }
Плохая новость в том, что в джаваскрипте нет нативного способа сделать полную копию объекта. Можно воспользоваться хитростью и перегнать объект в жсон и обратно, что, по сути, приведет к созданию нового объекта:
const objCopy = JSON.parse(JSON.stringify(obj))
К сожалению, при таком преобразовании будут утеряны любые объекты, которые не парсятся в жейсон (например, функции).
Хорошая новость в том, что всегда можно написать при необходимости функцию для копирования объекта самостоятельно или воспользоваться уже готовой из какой-нибудь библиотеки. Ну или писать, где можно, в неизменяемом стиле, чтобы не приходилось задумываться над такого рода проблемами.
Тестирование фронтенда снепшотами
Начал разбираться с автоматическим тестированием фронтенда. Тема оказалось сложной. Гугл выдает огромное число разнообразных библиотек и фреймворков для тестирования, причем не понятно, какие из них взаимозаменяемы, а какие нужно использовать вместе для разных целей. Пока что научился писать простейшие тесты при помощи двух библиотек: jest и react-testing-library.
Для примера приведу тесты для проверки работоспособности псевдоссылок для входа и регистрации в моем чатике.
В шапке есть две ссылки: Login и Sign up. Логика работы их такова:
- изначально формы логина и регистрации спрятаны,
- по клику на ссылку отображение соответствующей формы меняется со спрятанного на нормальное и наоборот,
- одновременно обе формы не должны отображаться.
Вот полностью код, который проверяет, действительно ли приложение работает, как описано выше:
import React from 'react';
import { Simulate, render } from 'react-testing-library';
import { Provider } from 'react-redux';
import { createStore } from 'redux';
import reducer from '../src/client/reducers';
import Main from '../src/client/components/Main.jsx';
const store = createStore(reducer);
test('Renders signup and signin forms', () => {
const { getByText, container } =
render(<Provider store={store}><Main /></Provider>);
expect(container.firstChild).toMatchSnapshot();
Simulate.click(getByText('Login'));
expect(container.firstChild).toMatchSnapshot();
Simulate.click(getByText('Sign up'));
expect(container.firstChild).toMatchSnapshot();
Simulate.click(getByText('Sign up'));
expect(container.firstChild).toMatchSnapshot();
});
Работает он так:
1. Рендерим реакт-компонент при помощи render из react-testing-library. В результате извлекаем ДОМ-объект container и вспомогательную функцию getByText, она пригодится чтобы находить ноды с нужным текстом.
2. Проверяем, что получившийся ДОМ соответствует образцу, хранящемуся в снепшоте. Снепшот — это состояние дерева, которое строит реакт для рендеринга приложения.
При первом запуске тестов строка expect(container.firstChild).toMatchSnapshot() создает и сохраняет файл со снепшотом в папку __snapshots__, а при каждом следующем запуске сравнивает этот сохраненный снепшот с новым и смотрит, что поменялось. Если ничего не поменялось, то тест считается пройденным. Если поменялось, то тест падает, выводит разницу между снепшотами и предлагает обновить снепшот, если изменение преднамеренное.
Вот кусочек первого снепшота, который показывает форму входа:
<div
class="loginForm"
id="loginForm"
style="display: none;"
>
<form>
<label
class="loginForm__label"
>
Username:
<input
id="loginUsername"
type="text"
value=""
/>
<br />
</label>
<label
class="loginForm__label"
>
Password:
<input
id="loginPassword"
type="password"
value=""
/>
<br />
</label>
<button
class="btn btn--secondary"
type="submit"
>
Login
</button>
</form>
<span
class="error"
/>
</div>
Обратите внимание на стиль дива display: none. Изначально форма должна быть спрятана, поэтому пока все идет как и запланировано.
3. Дальше мы находим ссылки, работу которых пытаемся проверить, имитируем клики по ним, и проверяем, что приложение перерендерилось так, как было задумано.
Simulate.click(getByText('Login'));
expect(container.firstChild).toMatchSnapshot();
Если после нажатия ссылки форма не появляется, то тест выведет примерно такую ошибку:
FAIL __tests__/test.jsx
● Renders signup and signin forms
expect(value).toMatchSnapshot()
Received value does not match stored snapshot "Renders signup and signin forms 2".
- Snapshot
+ Received
- style="display: block;"
+ style="display: none;"
Минуc такого метода со снепшотами в том, что им нельзя тестировать по TDD, когда ты сначала пишешь тесты, а потом удовлетворяющий этим тестам код. Тут нужно сначала написать код, удостовериться каким-то другим способом, что он работает, и только потом можно будет поснимать с него снепшоты. То есть подход помогает удостовериться, что в процессе последующей работы ничего не сломается, но не помогает написать первоначальную реализацию.
Далее предстоит разобраться в том, как писать тесты посложнее: например, как проверить работу риал-тайм приложения с сокетами, и как протестировать фронтенд с бекендом вместе.
Redux
Закончил на хекслете курс по редуксу. Эта библиотека предназначена для управления состоянием и сама по себе оказалась неожиданно простой. Покажу основные тезисы на примитивном примере.
Нужно сделать приложение, которое показывает счетчик и две кнопки, которые увеличивают и уменьшают значение счетчика. Вот такое: https://jsbin.com/jasidut/edit?html,output
Для описания состояния такого приложения достаточно одного числа, которое символизирует значение счетчика. Состояние хранится в специальном объекте под названием store. Чтобы посмотреть, что в этом объекте находится, есть метод getState():
store.getState();
// 0
Чтобы поменять состояние существует единственный способ: передать в store другой объект под названием action.
Action — это обыкновенный джаваскриптовский объект, который описывает изменение, которые мы хотим произвести над состоянием. В нем есть должно быть одно обязательное свойство type и сколько угодно опциональных свойств с любыми данными.
Action передается в store при помощи метода dispatch(). Например, чтобы увеличить значение счетчика, нужно передать action с типом INCREMENT:
store.getState();
// 0
store.dispatch({ type: 'INCREMENT' });
store.getState();
// 1
То, как именно обновляется состояние в зависимости от переданного сообщения, определяется специальной функцией под названием reducer, которая принимает два аргумента: state и action. От этой функции требуется, чтобы она правильно обновляла состояние в зависимости от переданного action. В примере со счетчиком редьюсер будет выглядеть так:
const reducer = (state = 0, action) => {
switch (action.type) {
case 'INCREMENT':
return state + 1;
case 'DECREMENT':
return state - 1;
default:
return state;
}
};
Эту функцию называют редьюсером из-за сходства со стандартной операцией над списком reduce. В редьюс передают функцию, которая последовательно обновляет аккумулятор основываясь на элементах в списке. Так же и редьюсер после каждого задиспатченного экшена обновляет состояние.
Наконец, нужно создать хранилище на основе редьюсера:
import { createStore } from 'redux';
const store = createStore(reducer);
Последний метод у хранилища называется subscribe(). Он принимает функцию, которая будет выполняться после каждого обновления состояния. Вот так, например, можно автоматически выводить состояние хранилища в консоль после каждого обновления:
store.subscribe(() => console.log(store.getState()));
На этом возможности редукса заканчиваются. Сложности начинаются, когда нужно подключить редукс к реакту и написать что-то посложнее счетчика. Для этого есть куча дополнительных библиотек, которые и рассматриваются в хекслетовском курсе: react-redux для интеграции с реактом, redux-form для работы с формами, redux-actions для того, чтобы не создавать экшены вручную, и так далее. В определенный момент начинаешь путаться в этом разнообразии, пытаясь держать в голове все эти разрозненные элементы.
Для особо любознательных рекомендую дополнительно серию видосов по редуксу, записанных его автором: https://egghead.io/courses/getting-started-with-redux. Там он между делом показывает, как написать собственную реализацию такой же библиотеки.
Чат
Пришло время показать, что я делал последний месяц: chat.ignat.co
Мне предложили тестовое задание, в котором нужно было сделать мессенджер в реальном времени. По условию, приложение должно быть сделано на следующем стеке:
- Сервер на express,
- База данных mongodb,
- Фронтенд на react или angular.
Из вышеперечисленного, на тот момент, я имел отдаленное представление только про экспресс, поэтому поначалу не знал даже с какой стороны подступиться к заданию. Вначале стал вникать по отдельности в нужные библиотеки.
В первую очередь пришлось разобраться, как сделать в приложении взаимодействие нескольких юзеров в реальном времени. Нагуглил для этого библиотеку socket.io. У них на сайте хороший туториал как раз на примере чата.
Потом начал думать, как прикрутить чат к базе данных. Использовал для этого облачный сервис mongodb atlas, что сильно упростило жизнь. Создаешь через веб-интерфейс базу и коннектишься к ней из своего приложения через mongoose, очень удобно.
Когда приложение более-менее заработало, нужно было переписать фронт на специально предназначенном для этого фреймворке, для чего начал изучать реакт. В этом помогли хекслетовский курс и официальный гайд. Сам реакт оказался не таким страшным, как я себе представлял. Курс на хекслете получилось пройти примерно за неделю. В предыдущих курсах про асинхронность и генераторы столько же времени иногда уходило на отдельные задания.
В конце итоговое задеплоил на digital ocean при помощи nginx и pm2. К сожалению, роскомнадзор на днях начал банить их адреса, из-за чего мой чатик может быть недоступен читателям в РФ. Похоже, что следующим навыком в обучении веб-разработке придется осваивать умение противостоять блокировкам.
Итоги третьего проекта на Хекслете
Закончил на Хекслете третий проект по фронетенду. По сравнению с предыдущими двумя он имеет пару отличий.
- Это первый проект, имеющий прямое отношение к вебу, так как в нем нужно сделать сайт, а не консольную программу.
- В нем заметно меньше прямых инструкций. Сказано, что приложение должно делать, но способ, которым этого достичь, приходтится искать самостоятельно.
В ходе проекта узнал много нового:
surge.sh
Проект деплоится на surge.sh. Сервис оказался крутейшим — статический сайт деплоится одной командой из терминала, что намного удобнее digital ocean, которым я пользовался раньше. Дополнительно подключил сурж к тревису. После каждого коммита он автоматически запускает тесты, и, если они проходят, проект сразу деплоится.
Вебпак
Я хоть и имел дело с вебпаком до этого, но не использовал многие из его возможностей. Научился генерировать из вебпака html и подключать через него бутстрап.
Бутстрап
Научился пользоваться фреймворком для верстки страниц, которым пользуется, половина сайтов в интернете. Он позволяет добавлять на страницу стандартные элементы, не задумаваясь, о том, как создавать их вручную.
RSS
Научился работать с RSS. Несмотря на то, что читаю новости при помощи RSS примерно лет десять, никогда не задумывался о том, как оно устроено внутри. Оказалось, что RSS-поток — это просто xml-файл определенной структуры.
Промисы
Пожалуй, основная задача проекта — научится писать асинхронный код при помощи промисов. Для скачивания RSS по http используется библиотека axios. Сложнее всего оказалось реализовать автоматическое обновление RSS-потоков при помощи промисов.
Также темой проекта, насколько я понял, было показать студенту, насколько это муторное дело — работать с ДОМом вручную. После осознания этого на собственном опыте намного проще понять, для чего предназначены всякие фронтенд-фреймворки типа реакта.
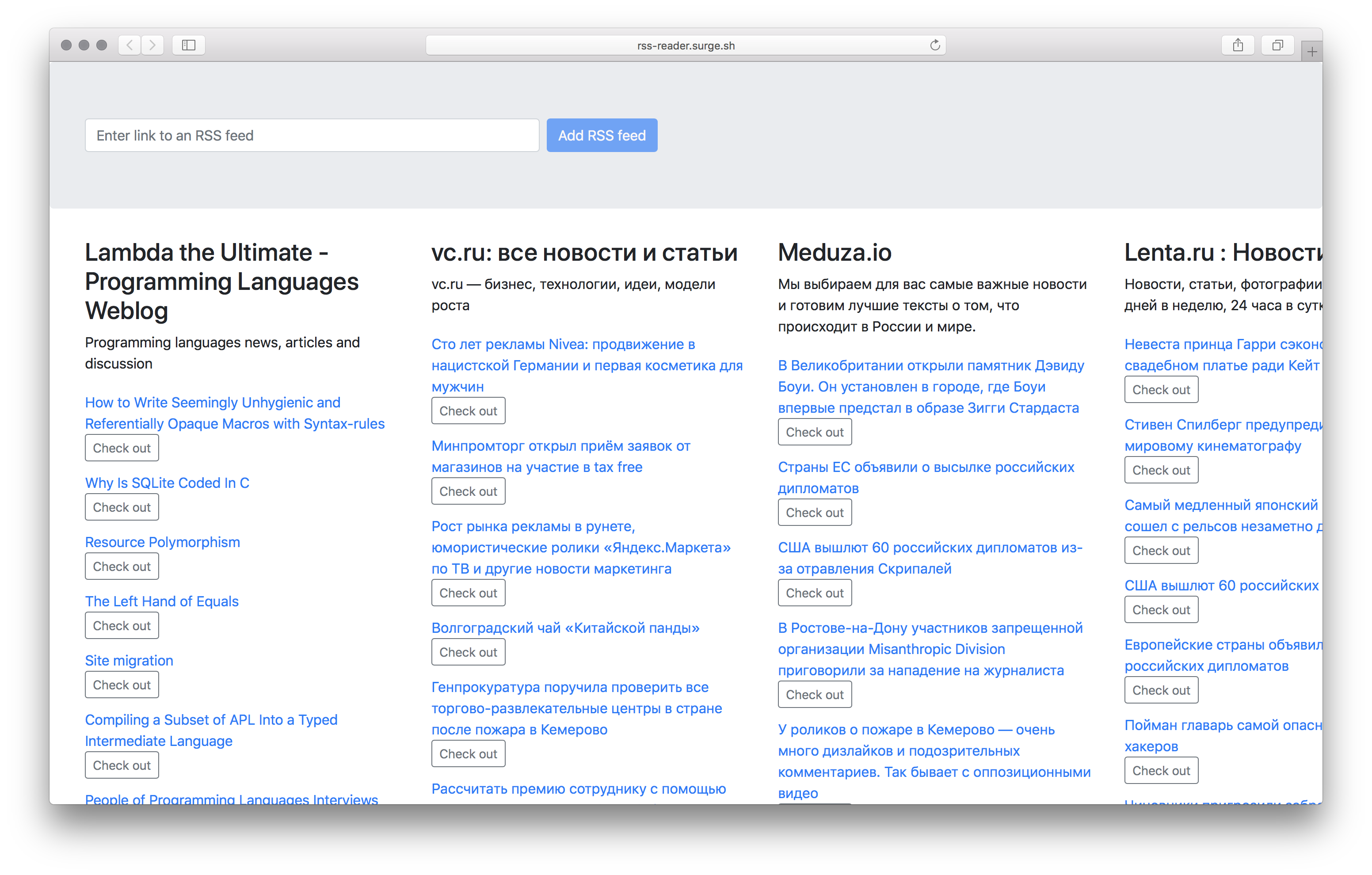
rss-reader.surge.sh — задеплоенное приложение. Через форму добавляются RSS-потоки, например http://lambda-the-ultimate.org/rss.xml. Статьи из добавленных потоков обновляются каждые пять секунд.
Начало третьего проекта на Хекслете
Привет. Прошу прощения за долгое отсутствие, последнее время не получалось писать посты по двум причинам.
Во-первых, подвернулось интересное тестовое задание на создание веб-приложения. В задании однвременно несколько новых для меня технологий, на изучение которых уходит много врменени.
Во-вторых, капитально застрял на последних уроках из хекслетовского курса «синхронная асинхронность». В одном из них нужно при помощи сопрограмм написать функцию для работы с асинхронным кодом на основе промисов. Уже неделю не могу до конца понять эти новые концепции, так что написать о них пост пока не получается.
Чтобы надолго не застревать на одном месте начал проходить следующий курс про DOM API. Он пошел легче, многое из него я уже изучал до этого для работы над собственным проектом.
Вчера на хекслете начался третий проект по фронтенду, в котором требуется написать приложения для чтения рсс. Боялся, что не смогу участвовать из-за не до конца сделанных курсов, указанных в требованиях к проекту. К счастью, ментор проекта Кирилл сказал, что можно начинать и без пары незаконченных уроков, так что на этой неделе попробую его сделать и писать почаще посты о процессе.
Smoosh
Наткнулся на поучительную историю, которая прямо сейчас разворачивается в мире джаваскрипта.
Я уже как-то рассказывал про занимательную особенность жс, которая позволяет определять объектам собственные методы и даже переопределять уже существующие. Использование этой возможности называется «манки патчинг» и, как оказалось, имеет далеко идущие последствия.
Лет десять назад, когда никаких ES6, бабелей и нпмов не было и в помине, была написана библиотека «mootools». Она добавляла при помощи манки патчинга всякие удобные методы, которые по умолчанию в языке отсутствовали. Среди таких методов был, помимо прочего, flatten, делающий массив плоским:
[1, 2, [3, 4], 5].flatten()
// [1, 2, 3, 4, 5]
Библиотека пользовалась популярностью и все бы было хорошо, но в очередную версию джаваскрипта захотели добавить flatten по умолчанию. Если это сделать, то весь код, написанный с использованием flatten из mootools, будет вместо него вызывать нативный метод. А так как они имеют разный интерфейс, это приведет к ошибкам.
Теперь на гитхабе ожесточенно спорят, как поступить: дать методу какое-нибудь другое название вроде smoosh, чтобы избежать конфиликта; или оставить каноничное название, а тот, у кого из-за этого сломается сайт — сам виноват: https://github.com/tc39/proposal-flatMap/pull/56
Кстати, ровно по такой же причине метод, проверяющий наличие элемента в массиве, называется includes — contains уже использовался в том же mootools.
Не знаю кто виноват в этом бардаке: создаели языка, которые предоставили такие возможности, или создатели библиотек, которые эти возможности неправильно используют. Но пугает решимость, с которой сообщество готово поломать кучу старых сайтов, лишь бы не давать методу глупое название.
Из всего этого можно сделать следующий вывод: не стоит рассчитывать, что написанный тобой код на джаваскрипте будет работать через 5–10 лет.
Автоматное программирование
Закончил курс «автоматное программирование». В нем поведение программы описывается на основе математической модели конечных автоматов. Существует некоторое количство состояний, в которых программа может находится, а выполнение программы представляет собой вызов функций перехода из одного состояния в другое. В курсе знакомят с библиотекой на джаваскрипте, при помощи которой эту модель можно реализовать: https://github.com/jakesgordon/javascript-state-machine
В целом эта абстракция настолько простая и понятная, что после продолжительных попыток разобраться с прототипами и коллбеками, курс про автоматы кажется прямо-таки глоктком свежего воздуха. Хочется посмотреть, как это применяется на практике, а то сам пока не очень представляю.
Асинхронное программирование
Вчера закончил курс «асинхронное программирование». Чем дальше продвигаюсь по курсам хекслета, тем становится сложнее. Последние два задания не мог решить по нескольку дней. Наверное потому, что способ программирования, описаный в этом курсе, сильно не похож на все, что я видел до этого.
Поясню на примере. Я привык, что код будет выполняться строго в том порядке, в каком он записан в исходнике:
console.log('раз');
console.log('два');
console.log('три');
// раз
// два
// три
В синхронном программировании все так и есть. Но существуют асинхронные функции, которые этот порядок ломают. В ноде, например, есть такая функция setTimeout. Она принимает на вход функцию, и количество миллисикунд, после истечения которого, эта функция будет вызвана.
Вот тут setTimeout подождет две секунды прежде чем вызвать функцию, печатающую в консоль «два».
console.log('раз');
setTimeout(() => console.log('два'), 2000);
console.log('три');
Какой будет результат этого кода? Предыдущий опыт подсказывает, что сначала напечатется «раз». Потом две секунды ничего не будет происходить. Потом напечатается «два» и, в самом конце, «три». На деле порядок окажется другим:
// раз
// три
// два
Так происходит потому что нода, встретив асинхронную функцию, не ждет ее выполнения, а откладывает переданную в нее функцию на потом. А тем временем продолжает выполнять остальные синхронные операции далее по тексту.
Получается что-то вроде очереди в макдаке: когда кто-то заказывает бургер, это не мешает принимать заказы у следующих в очереди и выдавать им еду, если их заказ приготовился раньше.
В джаваскрипте асинхронность дает примерно такую же выгоду как и в фастфуде: если на выполнение какой-то операции требуется много времени, это не будет откладывать выполнение остальных.
Напоследок вот неплохая статья про то, как в джаваскрипте выполняются асинхронные функции.
Итоги второго проекта на хекслете
Закончил вчера второй проект на хекслете: «вычислитель отличий». Результат моих трудов в нпм: https://www.npmjs.com/package/compare-files.
Для меня этот проект оказался значительно сложнее первого. В первом проекте была одна задача, с которой пришлось долго разбираться: организация правильной архитектуры. Послее ее решения все пошло довольно легко. Во втором же проекте пришлось почти на каждом шаге подолгу думать, какого решения от меня ожидают. Причем по итогу не везде удалось до этого решения дойти.
К сожалению, не находил времени описывать в блоге ход проекта, как я это делал в прошлом, так как боялся не успеть закончить его вовремя. И то, в итоге едва успел, отправив последний шаг на проверку вечером воскресенья.
В общем, участие во втором проекте лишний раз напомнило простую истину, что по-настоящему чему-то научиться можно только на практике.
Предполагается, что в проетке нужно применять знания из курсов: построение аст, обработка деревьев, полиморфизм. Пока смотришь уроки, все кажется довольно простым и понятным. Но как только появлется необходимость самому применить те же концепции в немного другом контексте, то все уроки почему-то сразу выветриваются, а мозг самопроизвольно начинает изобретать велосипеды.